We Built AI Agents for Data Analytics — Here’s What We Learned the Hard Way
We’ve spent the last year building PlotStudio AI — a multi-agent system that takes raw data and produces complete analytical reports. Along the way we:
Broke it → Fixed it → Broke it again → Fixed it better.
Every time, the lesson was the same.
The biggest threat to a multi-agent system isn’t a lack of intelligence. It’s over-orchestration.
- Rigid plans compound wrong assumptions
- Rigid prompts can’t adapt when the agent encounters something the prompt didn’t anticipate
- Rigid orchestration prevents the agent from doing what it’s smart enough to do on its own
Every failure we encountered traced back to the same root cause: we were over-orchestrating the system and under-investing in the context we gave it.
This post is about the three lessons that changed everything for us. These are the biggest AI engineering lessons we’ve learned as we continue to build what we believe is the best data analyst agent.
The Orchestration Problem
Don’t over-orchestrate. Embed adaptive tasks within a structured workflow — let the agent decide where it matters.
The Art of Prompting
Lean, iterated prompts that give agents the right mental model — not duct-tape rules that bloat and break.
The Domain Knowledge Gap
Generic stats fail. The agent needs domain-specific depth, not just data science breadth.
The Orchestration Problem
There’s no shortage of agent orchestration frameworks:
LangGraph
Graph-based agent workflows
CrewAI
Role-based multi-agent teams
AutoGen
Multi-agent conversations
OpenAI Agents SDK
Handoffs and guardrails
They all make it easy to define agents, wire up handoffs, and build DAGs of tasks. And that’s exactly the trap.
The Orchestration Trap
A quick Google search for “multi-agent orchestration” returns diagrams like this:
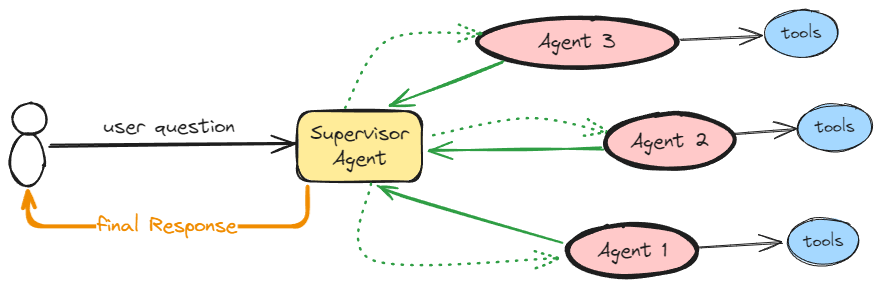
What if the supervisor picks the wrong agent? Or the right agent errors out mid-task? This is a single-turn diagram — real agentic systems are multi-turn. Can a downstream agent recognize it’s wrong for the job and route back? In most implementations, no.
When you come from a data engineering or MLOps background, orchestration feels natural. You build DAGs. You define dependencies. You create deterministic pipelines where step A feeds into step B. That mental model works brilliantly for ETL jobs. It’s the wrong model for AI agents.
We use orchestration too — we have a planner that breaks the analysis into subtasks, and a data analyst agent that executes them. But the lesson we learned is that the goal isn’t to build orchestration. It’s to build the most minimal, effective, and adaptive orchestration possible. And that’s actually much harder than building a rigid DAG.
If your mental model for building agents is the same one you use for ETL pipelines, you’ve already lost.
Our problem wasn’t that the agent followed a DAG — we actually wanted that. We invested heavily in making the planner as thorough as possible. The problem was a deeper realization: good data analysis fundamentally cannot be fully planned beforehand.
This is a key distinction. Some workflows can be planned as a DAG upfront:
- ETL pipelines
- Document processing
- Customer support routing
These have predictable steps with well-defined inputs and outputs. A rigid orchestration layer works because the problem space is deterministic.
But data analysis is philosophically different. It’s an exploration and investigation task.
You can have all the information about a dataset upfront:
The Schema
The Distributions
The Domain Context
And still not know what the right analytical approach is until you start running steps and seeing what comes back:
| What You Planned | What the Data Told You |
|---|---|
| Fit a linear regression | Residuals reveal a nonlinear relationship |
| Cluster customers into segments | Groups don’t separate meaningfully |
| Decompose a time series for seasonality | The seasonality pattern doesn’t exist |
| Fit a threshold model for a breakpoint | Confidence intervals are so wide it’s meaningless |
| Run a statistical test for significance | Significant p-value, but negligible effect size |
Each finding changes what you should do next. As you uncover results, they lead you down paths the plan never anticipated. Then what do you do? In a rigid DAG, you do nothing — you move to the next step and pretend the previous one worked. In real analysis, you pivot. The plan is always a hypothesis — and hypotheses need to be tested, not just executed.
For a while, we didn’t see this. Our orchestration and context engineering were strong enough that we were outperforming other AI analytics tools comfortably. We were happy with the results. But as we pushed into harder analytical questions, we noticed a gap.
The agent wasn’t failing — it was producing analysis that read like a competent junior analyst. Solid fundamentals, clean execution, but missing the depth that comes from iteration and discovery. The planner did its best. The agent followed the DAG faithfully. The results weren’t wrong — they just weren’t deep enough.
Closing that gap required giving the agent something a fixed DAG can’t provide: the ability to explore.
The solution wasn’t to remove the DAG. It was to embed adaptive tasks within a structured workflow.
We created exploration subtasks — nodes in the plan that don’t have a fixed implementation. They have a goal and suggested approaches, but the executing agent decides how to pursue them, how many attempts to make, and when to move on.
The overall structure is still a DAG. The user can still see the plan. But individual nodes within it can be:
- Exploratory
- Iterative
- Adaptive
The hybrid that works: a visible, structured plan where individual nodes can be exploratory. Structure for transparency. Exploration for depth.
A Real-World Example
An external evaluator tested our agent on Bitcoin OHLCV data. The planner created a structured analysis:
- Rolling averages
- Basic returns
- Naive trend detection
The standard tools for this domain — RSI, MACD, Bollinger Bands — were never used. The agent knew they existed — it cited them in its own self-critique on page 4 of a polished report built on weak foundations.
On simpler datasets like Ames Housing, our agent looked incredible. The plan was predictable:
- Data cleaning
- Feature visualization
- Regression model
- Residual analysis
But those problems don’t require the agent to deviate from a plan. When users asked harder questions, the agent would follow the plan, produce results, and then write in its own report that the analysis was insufficient.
The agent already knew what it should do. We just weren’t giving it the chance to do it.
We couldn’t remove the planner — users need transparency, not a black box. So instead, we changed what a plan means. The planner is no longer a prescription — it’s guidance. The agent doing the work sees the actual data, the actual results, and the actual edge cases. It should be the one making the decisions.
Rigidity in agentic systems doesn’t just reduce quality — it compounds errors. Every rigid step that inherits a wrong assumption from the previous step makes the final output look more confident and more wrong at the same time. The fix isn’t removing structure. It’s making structure flexible enough that the agent can act on what it knows.
Why We Hit the Wall
We originally followed OpenAI’s “A Practical Guide to Building Agents” closely — specialized agents, explicit handoffs, developer-controlled routing. It worked well for most analyses. But it broke down precisely where data analysis demands the most from an agent:
- Deeper exploration when the first approach doesn’t work
- Adaptiveness when results contradict the plan
- The ability to recognize blind spots mid-analysis
When we benchmarked against models running with full autonomy on those harder questions, we weren’t better. Sometimes we were worse.
That’s when we found Anthropic’s “Building Effective Agents”, “Effective Context Engineering”, and “Writing Effective Tools” — and they described exactly our problem: don’t over-orchestrate. Invest in tool quality and context, not routing logic. The real engineering challenge is “finding the smallest set of high-signal tokens that maximize the likelihood of some desired outcome.”
| Dimension | OpenAI | Anthropic | AR5Labs |
|---|---|---|---|
| Starting point | Design the agent graph upfront | Start with one agent, add complexity only when measured | Minimal adaptive DAG with exploratory nodes |
| Control flow | Developer-defined routing and handoffs | Model decides autonomously | Structure as guidance, agent decides execution |
| Planning | Pre-defined transitions and guardrails | Model plans on the fly | Visible plan with adaptive tasks that can pivot |
| Biggest lever | Orchestration architecture | Tool quality and context | Context engineering + smart model routing |
| Error recovery | Guardrails catch bad I/O | Agent self-corrects in the loop | Exploration nodes self-correct; errors don’t cascade |
The more you orchestrate, the more you constrain. Structure sets the direction. Autonomy handles the terrain.
The Art of Prompting Agents
There’s a misconception that you can just plug in a strong model and let it figure things out. You can’t. We tried.
The Duct-Tape Prompting Problem
Most teams prompt like this:
- Run the agent
- See it do something wrong
- Add “don’t do that” to the prompt
- Run again, see a new issue
- Add another patch
- Repeat until the prompt is a wall of contradictory instructions held together with duct tape
We call this duct-tape prompting — and it’s the most common failure mode in production agent systems.
Each patch fixes one symptom without addressing why the agent made that decision in the first place. After 20 patches, the prompt is so cluttered with “don’t do X” rules that the agent can’t distinguish the important constraints from the noise. And every new patch risks breaking a previous one.
At AR5Labs, we don’t duct-tape. We treat prompt development as a structured engineering process:
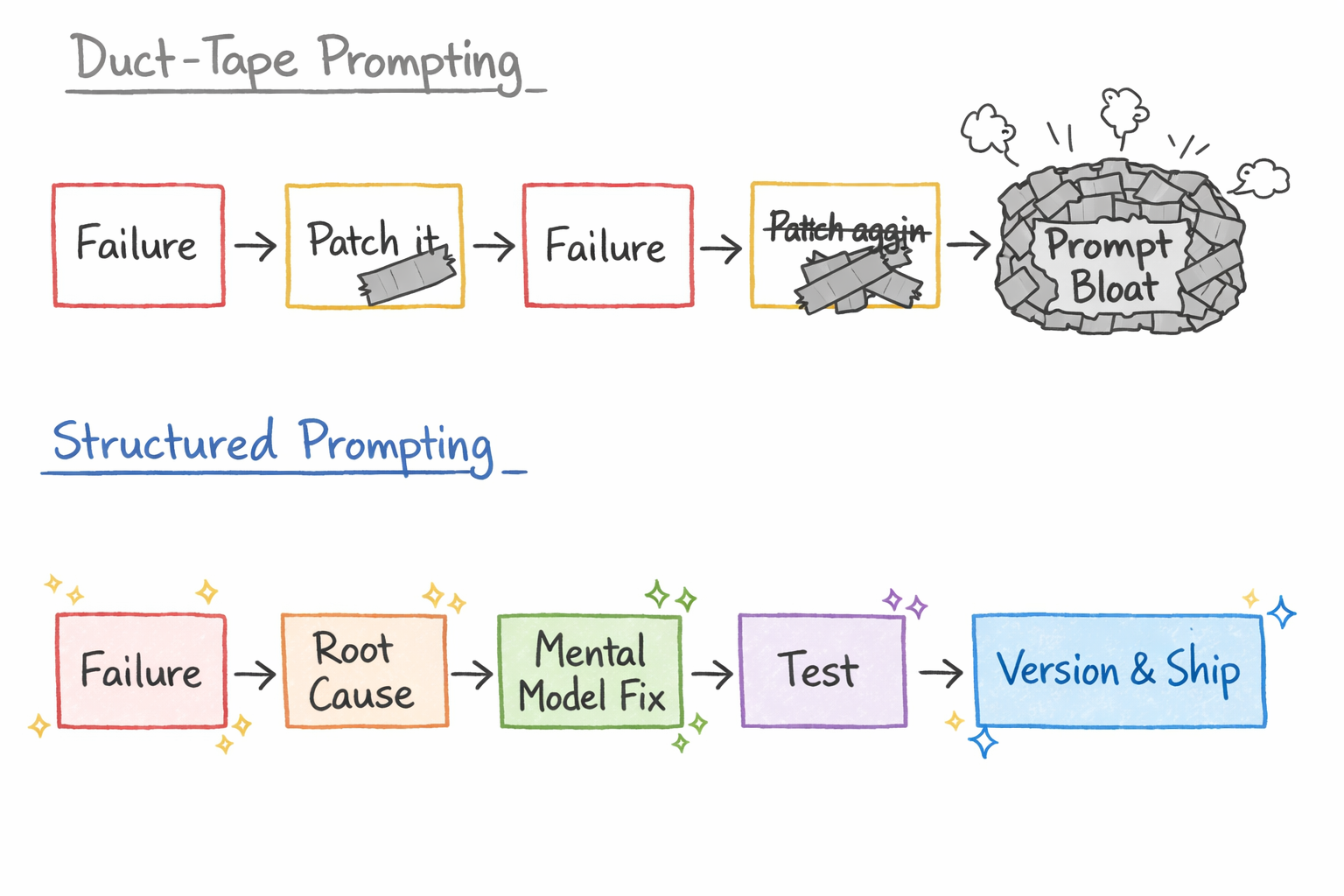
The difference: duct-tape prompting adds rules. Structured prompting changes mental models. When the agent makes a wrong decision, the fix isn’t “don’t do that.” It’s giving the agent a better framework for making that class of decision correctly every time.
The Numbers Tell the Story
Prompting agents is deeply iterative. Our data analyst agent prompt is on version 53. Our query understanding prompt is on version 24. Our Python coding prompt is on version 21. Each version represents a failure mode we discovered, diagnosed, and fixed.
But the growth wasn’t linear. Our prompts went through cycles of growth, bloat, and lean rewrites:
| Agent Prompt | Versions | v1 Words | Peak Words | Current Words |
|---|---|---|---|---|
| Data Analyst Agent | 53 | 5,778 | 14,881 (v47) | 7,441 (v53) |
| Query Understanding | 24 | 5,585 | 12,320 (v22) | 7,944 (v24) |
| Python Coding | 21 | 2,070 | 3,162 (v11) | 1,693 (v21) |
Growth → Bloat → Lean Rewrite. Prompts grow as you fix failures. They peak when they’re bloated with duct-tape rules. Then you stop and rewrite — distilling dozens of “don’t do X” patches into a clean mental model that handles the same cases in fewer words. Our DA agent prompt peaked at 14,881 words before we cut it nearly in half. The current version is leaner and better.
Eventually, you converge into the perfect agent prompt — one that encodes every failure you’ve seen, every edge case you’ve handled, every mental model that works. That prompt is worth your whole company. And it’s not something you write on day one.
The philosophy we arrived at: tailored, iterated, lean prompts that make your agent think like a data scientist with zero blind spots. Not a wall of rules. Not a generic instruction set. A precise mental model — refined across 53 versions, stripped of every unnecessary word — that gives the agent the judgment to handle whatever the data throws at it.
You can see the tension: covering every edge case pushes the prompt toward bloat. But a lean prompt risks blind spots. You have to exhaust every failure mode and keep the prompt minimal. That tug and pull — between the over-orchestration trap from the first section and the lean, context-driven prompt philosophy — is the fundamental challenge of building agents. It never fully resolves. You just get better at navigating it.
The Domain Knowledge Gap
The second problem was subtler.
Our agent could analyze anything — but it analyzed everything the same way.
| Data | Agent’s Approach |
|---|---|
| Sales data | EDA, correlations, regression, forecasting |
| Clinical trial data | Statistical tests, group comparisons, classification |
| Network traffic logs | Anomaly detection, clustering, time series decomposition |
The agent was genuinely capable. That’s what made the gap so hard to spot.
- It could adapt its approach to different datasets
- Run proper statistical tests
- Build models
- Compare effect sizes
The output looked like expert analysis — and to some extent it was. Real depth, proper test selection, nuanced interpretation.
We didn’t see a problem at first because even very competent data professionals converge on the same toolkit — pandas, scikit-learn, matplotlib, the same battery of statistical tests.
When you’ve seen enough analysts work across domains, the workflow looks interchangeable. So when our agent did the same thing, it felt normal. It took us longer than it should have to realize that the sameness was the problem — it applied the same general-purpose data science toolkit every time, without the domain-specific knowledge that separates a competent analysis from a meaningful one.
This is what happens when your analytical pipeline is domain-agnostic. It defaults to the same generic statistical toolkit regardless of what the data actually represents.
But domains have fundamentally different analytical languages:
| Domain | What Generic Stats Does | What the Domain Actually Needs |
|---|---|---|
| Financial Time Series | Mean price, rolling average, basic returns | RSI, MACD, Bollinger Bands, GARCH volatility |
| Clinical Trials | “X% had outcome Y” | Kaplan-Meier survival curves, Cox proportional hazards |
| Genomics | T-tests on 20,000 genes (~1,000 false positives) | FDR correction, compositional transforms, negative binomial models |
| Geospatial | Correlation between location and outcome | Moran’s I, kriging, geographically weighted regression |
| Supply Chain | Average demand forecast | Bullwhip effect quantification, Croston’s method |
| Insurance | Mean loss, standard deviation | Extreme Value Theory, Pareto distributions, tail risk |
| Sports Analytics | Goals scored, batting average | xG (expected goals), WAR, park-adjusted metrics |
The pattern is consistent across every domain we looked at: generic statistical methods produce technically correct but analytically useless results when applied to domain-specific data.
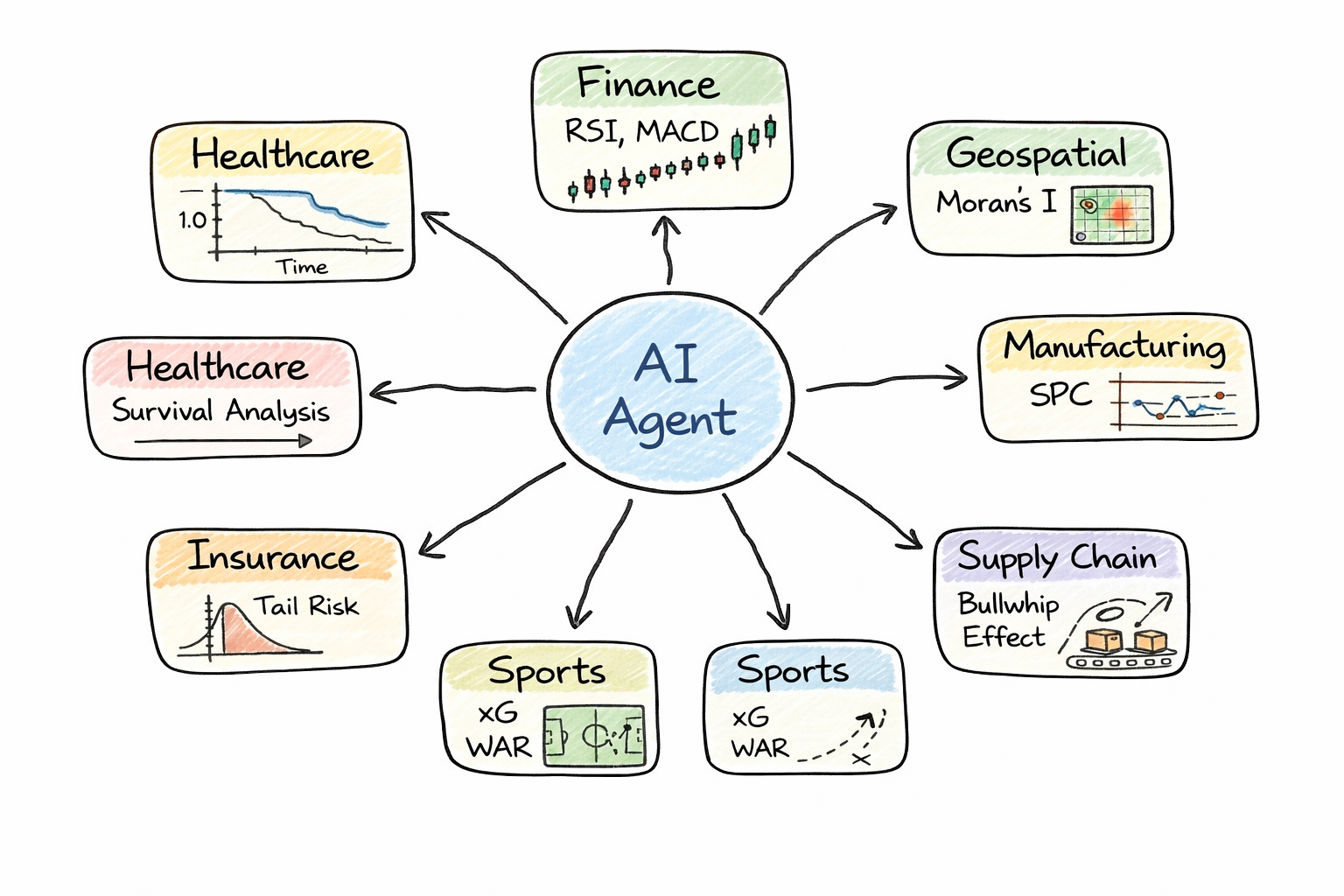
Why Generic Statistics Fail
This isn’t a theoretical concern. Here are the recurring patterns we found across every domain where standard statistical methods break down:
The Independence Assumption
Standard statistical tests assume data points are independent. This is violated in:
- Time series — today’s price depends on yesterday’s
- Geospatial data — nearby locations are correlated (Tobler’s First Law)
- Network data — connected nodes influence each other
- Sensor/IoT data — adjacent sensors measure overlapping phenomena
An agent that runs a t-test on spatially autocorrelated data will report a “significant” difference that doesn’t exist.
The Normal Distribution Assumption
Most standard methods assume data is roughly normally distributed. This breaks catastrophically for:
- Insurance losses — heavy-tailed Pareto distributions where the mean may be mathematically infinite
- Cybersecurity events — power-law distributed; 5% of vulnerabilities cause 95% of attacks
- Financial returns — fat tails, skewness, and kurtosis far beyond normal
- Gene expression — zero-inflated count data that breaks t-test assumptions
An agent that computes “mean ± 2 standard deviations” on a Pareto distribution is producing numbers that have no statistical meaning.
The Representation Problem
Sometimes the raw data needs to be transformed into a completely different representation before any analysis makes sense:
- Audio → frequency domain (FFT, spectrograms, MFCCs)
- Financial prices → log-returns, not raw prices
- Clinical outcomes → survival curves, not simple percentages
- Ecological abundance → compositional transforms (CLR), not raw counts
An agent analyzing raw audio amplitudes with standard statistics is like analyzing the individual characters in a novel to understand the plot.
The failure is never in the computation. The numbers are always correct. The failure is in the choice of what to compute. That choice requires domain knowledge that no amount of Python proficiency can replace.
Dynamic Skills: Teaching an Agent to Adapt
This is where we’re heading. And it’s worth noting that Anthropic keeps building things that push agents in exactly this direction.
Earlier this year, Anthropic released Agent Skills — an open standard for packaging domain-specific knowledge into modular, loadable capabilities that agents can discover and use dynamically. The core idea:
- Skills sit as lightweight summaries in the agent’s context — just a few dozen tokens each
- Full details load only when needed — the agent decides which skills are relevant to the task
- Domain knowledge becomes modular — packaged, reusable, and shareable across agents
It’s the same pattern we arrived at independently. And it reinforces a theme running through this entire article: where OpenAI leans toward structured orchestration and explicit control, Anthropic keeps investing in making agents contextually smarter — better tools, better context, let the model adapt.
That philosophy aligns with what we’ve learned building a data analysis agent: the hard problem isn’t orchestration, it’s encoding the right domain knowledge so the agent knows what to do before it starts.
Instead of a one-size-fits-all analytical pipeline, PlotStudio AI is moving toward dynamic skill loading — the agent identifies the domain of the data and pulls in domain-specific analytical capabilities before planning the analysis.
The concept:
- Dataset profiling classifies the data into a domain (financial, clinical, geospatial, etc.) and assesses its complexity
- The agent loads domain-specific skills — statistical methods, validation criteria, and quality checks that are standard in that domain
- Planning adapts to the domain — the planner knows what tools are available and what analytical standards apply
| Data | Not This | This |
|---|---|---|
| Bitcoin OHLCV | Rolling averages | RSI, MACD, Bollinger Bands |
| Clinical trial | Percentages | Survival curves, Cox hazards |
| Manufacturing sensors | Means, standard deviation | Process capability analysis (Cp/Cpk) |
| Insurance claims | Mean loss, confidence intervals | Extreme Value Theory, Pareto tail modeling |
| Genomics expression | T-tests across 20K genes | FDR correction, negative binomial models |
| Network traffic logs | Mean ± 3 sigma anomaly detection | Power-law fitting, entropy-based baselining |
The agent doesn’t just know what the data is. It knows what the data demands.
What This Means for the Future of AI Analytics
We think the next generation of AI analytics agents will be defined by three capabilities:
Domain Awareness
Not just data awareness. The agent needs to understand that financial time series, clinical event data, and IoT sensor streams all contain timestamps — but demand completely different analytical approaches.
Adaptive Planning
The best human analysts don’t follow rigid plans. They form hypotheses, test them, and adjust. AI agents need the same capacity for mid-analysis course correction.
Honest Confidence
When the agent knows its approach is basic relative to the domain’s standards, it should say so — prominently, not buried on page 4. Users deserve to know when they need a domain expert.
Dynamic Skills
A growing library of domain-specific analytical capabilities that the agent loads based on what the data actually is — not a one-size-fits-all toolkit.
We’re building PlotStudio AI to be the first analytics agent that doesn’t just run your analysis — it knows which analysis to run, validates its own assumptions, and tells you when it’s uncertain.
Because the value of an analyst was never in their ability to compute. It was in their judgment about what to compute.
That’s what we’re teaching our agent.
See it in action
Upload your own data and see what domain-aware analysis actually looks like.
Try PlotStudio AI Free